Brief introduction to OpenMP. OpenMP编程介绍。
#OpenMP优点
- 对代码侵入性小,无需改变串行代码。
- 编译器实现的多线程,编译器优化效果好那么多线程效率就好。
#OpenMP运行机制
#1.Fork
由主线程(master thread)创建一组从线程(slave threads)。
- 主线程编号永远为0(thread 0)
- 不保证线程的执行顺序,即执行编号不是0,1,2,3而是乱序执行。
#2.Join
同步终止所有线程并将控制权转移回至主线程。
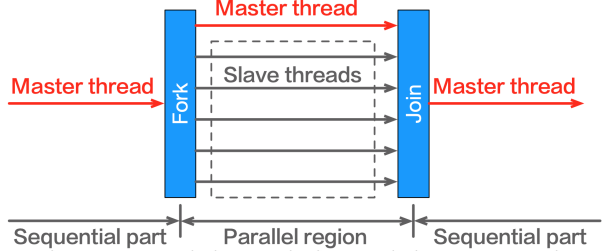 ※ 运行机制
※ 运行机制
#OpenMP宏作用范围
示例代码:
|
|
- 这个代码其实是有错误的,因为OpenMP宏只影响紧随其后的一个代码块,也就是my_rank那一句。
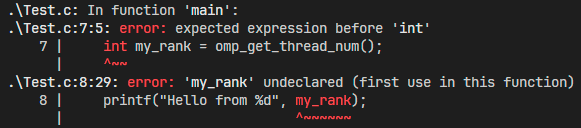
- 为了能够正确编译,需要给并行区域加上大括号
正确代码:
|
|
output:
Hello from 1
Hello from 0
Total Hello 4
Hello from 3
Hello from 2
#常用api && OpenMP宏
##pragma omp parallel
通过#pragma omp parallel指明并行部分。
|
|
output:
Hello World
Hello World
Hello World
Hello World
Hello World
Hello World
Hello World
Hello World
##pragma omp critical
指明下面的代码块是临界区,强制串行执行下面的代码。
|
|
以上代码有个缺点,假设有4个线程,Local_trap要操作n=4个数字,那么就要互斥4*4=16次。
改进版本,只需要互斥4次,每个线程一次:
|
|
#reduction(: )
归约操作:将一组数一直进行同一个操作直到得到一个最终结果。
- 在使用
reduction指令时,编译器会为每个线程创建一个私有副本的累加变量。在这个例子中,私有副本就是宏里面写的global_sum - 每个线程在并行循环中进行累加操作时,只会操作它自己的私有副本
global_sum - 当所有线程计算完成之后,这些私有副本会自动汇总到一起
|
|
#并行for循环
pragma omp parallel是下面相同的代码段用多线程跑,而不是将for分配到多线程跑。
|
|
output:
thread 3
thread 3
thread 0
thread 0
thread 0
thread 0
thread 1
thread 1
thread 1
thread 1
thread 3
thread 3
thread 5
thread 5
...
每个线程都跑了四次for循环。
要做到for的分配:即一个线程跑for的一部分。要用pragma omp for,可以合并为#pragma omp parallel for
|
|
output:
thread 0
thread 2
thread 3
thread 1
#不可并行的for循环
#1. 语法限制
#2. 数据依赖
- OpenMP编译器不会检查循环里面的数据依赖
|
|
-
有时候会得到正确结果
1 1 2 3 5 8 13 21 34 55 -
有时候不会
1 1 2 3 5 8 0 0 0 0
|
|
- sum: sum是一个累加的共享变量,会导致数据竞争。
- factor: 每个循环的factor依赖于上个循环的factor是正数还是负数,而且计算sum的factor也从上个循环来。
修改方法:
- sum用reduction
- factor每个循环独立计算
|
|
-
在并行区域外声明的变量,默认是共享的。如果想表示某个变量是线程私有的,要标明private。被标明private的变量不会进行默认初始化,在并行区域内一定要初始化。
1 2 3 4 5 6int i = 10; #pragma omp parallel for private(i) for (int j = 0; j < 4; ++j) { printf("Thread %d: i = %d\n", omp_get_thread_num(), i); } printf("i = %d\n", i);output: Thread 0: i = 0 Thread 3: i = -262146272 Thread 1: i = -262146512 Thread 2: i = -262146392 i = 10 -
在并行区域内声明的变量,默认是私有的。
-
循环计数器默认私有。
|
|
#omp_get_thread_num()
返回当前线程的编号。
#omp_get_num_threads()
返回总的线程数。
#num_threads(int)
- 用于指明线程数量。
- 当没有指明的时候,默认使用
OMP_NUM_THREADS环境变量。- 环境变量的值为系统运算核心数目(或超线程数目)。
- 可以使用
omp_set_num_threads(int)修改全局默认线程数 - 可使用
omp_get_num_threads()获取当前设定的默认线程数 num_threads(int)优先级高于环境变量
- num_threads(int)不保证创建指定数目的线程
- 受到系统资源限制
#schedule(type, chunksize)
OpenMP线程调度方式有四种方式。
-
静态调度(static) the iterations can be assigned to the threads before the loop is executed
- 调度由编译器静态决定
- 每个线程轮流获取chunksize个迭代任务
- 默认chunksize为n/threads
- 12个iterations,chunksize=1
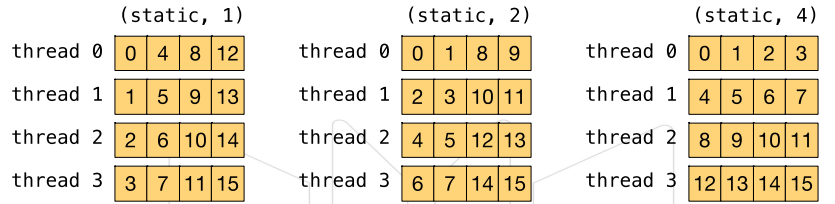
- 12个iterations,chunksize=2

-
动态调度(dynamic or guided) the iterations are assigned to the threads while the loop is executing
- 在运行中动态分配任务
- 迭代任务依然根据chunksize划分成块
- 线程完成一个chunk后向系统请求下一个chunk
-
自动调度(auto) the compiler and/or the run-time system determine the schedule
-
运行时调度(runtime) the schedule is determined at run-time
#同一线程的多个语句是否连续执行?
|
|
output:
hello(0) world(0) hello(4)
hello(1) world(1) hello(7)
hello(3) world(7) world(3)
hello(6) world(6) hello(5)
world(5) hello(2) world(4)
world(2)
说明线程之间并不保证执行顺序。线程多起来之后就会有调度上的问题,可能还没输出完就被调度下处理器了。
#同步机制
- OpenMP是多线程共享内存架构
- 线程可以通过共享变量通信
- 线程及其语句执行不具有确定性
- 共享数据可能造成竞争条件(race condition)需要解决互斥进入临界区
- 竞争条件:程序运行的结果依赖于不可控的执行顺序
- 必须使用同步机制避免竞争条件的出现
- 同步机制将带来巨大开销
- 尽可能改变数据的访问方式减少必须的同步次数
#OpenMP梯形积分法
梯形积分法估算𝑦 = 𝑓(𝑥)在[𝑎, 𝑏]区间上的积分
#串行版本
|
|