Brief introduction to Cuda Programming using C++.
使用C++进行Cuda编程,进行GPU并行化。
将计算密集型函数移植到GPU上以实现并行化,而其他顺序执行的代码仍然在CPU上执行
- 分配host内存,并进行数据初始化
- 分配device内存,并从host将数据copy到device上
cudaMalloc & cudaMemcpy
- 调用Cuda的核函数在device上完成指定的运算
<<<Blocks, Threads>>>
- 将device上的运算结果copy到host上
- 释放device和host上分配的内存
cudaFree & delete[] or free[]
声明在设备上执行的内核函数。主机代码也可以调用。
1
2
3
4
5
6
7
|
__global__ void add(int n, float *x, float *y) {
int index = threadIdx.x;
int stride = blockDim.x;
for (int i = index; i < n; i += stride) {
y[i] = x[i] + y[i];
}
}
|
声明仅在主机上执行的函数。这个关键字在大多数情况下是可选的,因为主机代码默认在主机上执行。
1
2
3
|
__host__ void printHello() {
printf("Hello from the host!\n");
}
|
声明仅在设备上执行的函数。这些函数不能从Host代码中调用,只能从其他设备或内核函数中调用。
1
2
3
|
__device__ float multiply(float a, float b) {
return a * b;
}
|
声明托管内存,使其在主机和设备之间可访问。
- 只能访问设备内存
- 必须返回void
- 不支持可变参数的函数
int func(int n_args, ...)
- 参数不可为引用类型(无法访问主机内存)
- 不支持静态变量(存在主机内存的数据段或者BSS段)
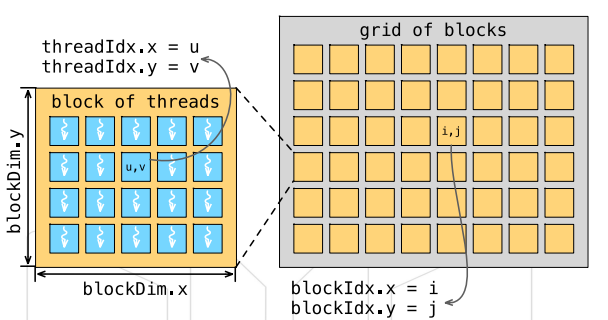
使用内置变量threadIdx, blockIdx, blockDim
1
2
|
int bid = blockIdx.x;
int tid = threadIdx.x;
|
他们是分隔的两个部分
已知长度为n的两个向量a与b,求向量c,使c[i]=a[i]+b[i]
1
2
3
4
5
|
void vector_add(int *a, int* b, int* c, int n){
for(int i = 0; i < n; ++i) {
c[i] = a[i] + b[i];
}
}
|
1
2
3
4
5
|
__global__ void vector_add(int *a, int* b, int* c){
int tid = threadIdx.x; // 获取线程编号
c[tid] = a[tid] + b[tid]; // 每个线程完成一个元素的加和
}
vector_add<<< 1, n >>>(a, b, c);
|
- a, b, c为主内存地址,GPU无法访问
- block中有最大线程数限制:n必须不大于1024
- 同一个block只在一个SM上执行:没有充分利用GPU计算资源
- 创建:
cudaMalloc 记得转为void**
- 拷贝:
cudaMemcpy
- 使用
cudaMemcpyHostToDevice与cudaMemcpyDeviceToHost指明拷贝方向
- 释放:
cudaFree
1
2
3
4
5
6
7
8
9
10
11
|
int *a_h, *b_h, *c_h; //_h常用来表明主机内存
int *a_d, *b_d, *c_d; //_d常用来表明设备内存
int n_bytes = sizeof(int)*n;
cudaMalloc((void**)&a_d, sizeof(int)*n); // 创建device内存
cudaMemcpy(a_d, a_h, n_bytes, cudaMemcpyHostToDevice); // 拷贝数据到device内存
... //same for b and cudaMalloc for c
vector_add<<< 1, n >>>(a_d, b_d, c_d); // 调用核函数执行GPU代码
cudaDeviceSynchronize(); // 等待所有加和操作完成,CPU再把结果拷贝回来
cudaMemcpy(c_h, c_d, n_bytes, cudaMemcpyDeviceToHost);
cudaFree(a_d); // 释放GPU内存
... //same for b and c
|
- 每个Block使用m个thread
- 确定thread的全局编号
1
2
3
4
5
|
__global__ void vector_add(int *a, int* b, int* c){
int tid = blockDim.x * blockIdx.x + threadIdx.x;
c[tid] = a[tid] + b[tid];
}
vector_add<<< n/m, m>>>(a, b, c);
|
- n无法被m整除
- 需对n/m向上取整,才是block的数量
- 需判断tid是否超过n
- 一般每个block里面的线程数目m是确定的
1
2
3
4
5
6
7
8
9
10
|
__global__ void vector_add(int *a, int* b, int* c, int n){
int tid = blockDim.x * blockIdx.x + threadIdx.x;
if (tid < n){ // 判断tid是否越界
c[tid] = a[tid] + b[tid];
}
}
int divup(int n, int m){
return ((n%m)?(n/m+1):(n/m)); // 向上取整
}
vector_add<<< divup(n,m), m>>>(a, b, c, n);
|
1
2
3
4
5
6
7
8
9
10
|
#define CHECK(call)
\{
\ const cudaError_t error = call;
\ if (error != cudaSuccess){
\ printf("Error: %s:%d, ", __FILE__, __LINE__);
\ printf("code:%d, reason: %s \n",
\ error, cudaGetErrorString(error));
\ exit(1);
\ }
\}
|
1
|
CHECK(cudaMalloc((void**)&a, n_bytes));
|
- Cuda
- 由核函数指明并行代码
- 主机代码调用核函数产生设备线程
- 用户决定每个线程处理的任务
- 异步执行,同步需要
cudaDeviceSynchronize()
- OpenMP
- 由预处理指令与{}指明并行区域
- 主线程产生从线程
- 由调度算法将任务分配到线程上
- 默认在并行区域结束的时候同步