Brief introduction to Cuda memory.
Cuda的内存模型。
#Cuda内存模型
#内存层次结构
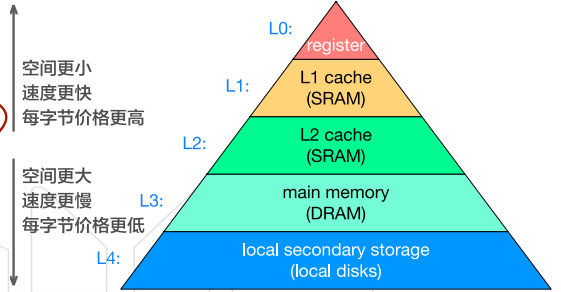 ※ 内存层次结构
※ 内存层次结构
#Cuda内存模型
- 每个线程
- 自己的寄存器
- 本地内存
- 每个线程块
- 共享内存,块中所有线程可以访问
- 所有线程
- 全局内存
- 常量内存
- 纹理内存
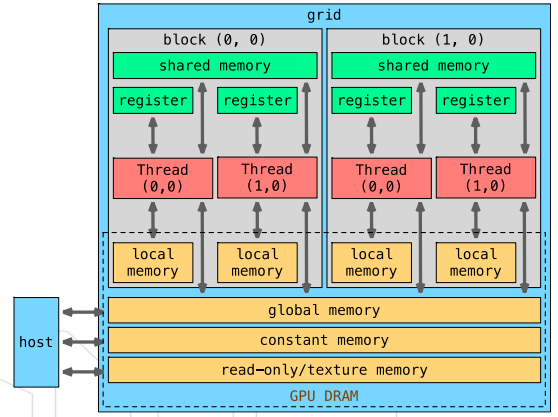 ※ Cuda内存模型
※ Cuda内存模型
#Cuda变量
- 没有修饰符的变量默认放在寄存器
- 超过寄存器限制的变量放在本地内存
- 极大降低程序效率
- 没有修饰符的数组被放在寄存器或者本地内存
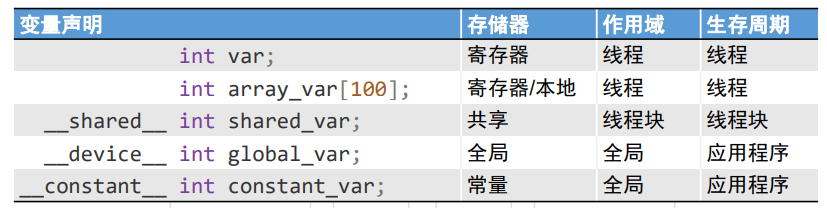 ※ Cuda变量
※ Cuda变量
- 每个线程的本地内存并非真实的物理存在
- 与全局变量存在同一块存储区域
- 计算能力2.0以上的CPU中,存储在SM的一级缓存以及设备的二级缓存
- 可能存放到本地内存的变量
- 编译时使用未知索引引用的本地数组(即引用的下标不是一个常量)
- 可能占用大量存储器空间的本地数组
- 不满足寄存器限定的变量
#共享内存
可编程的缓存
- 基于线程块
- 允许同一线程块中的线程共享部分数据
- 无法同步不同线程块中的线程
- 可以显式控制载入/同步数据 User-managed
- 片上存储 Extremely fast on-chip memory
- 读写速度非常快
- 带宽 > 1 TB/s
- 通过
__shared__进行声明- 生命周期跟
block的一致
- 生命周期跟
#全局内存
#动态全局内存
cudaMalloc()cudaMemcpy()cudaFree()
#静态全局内存
- 通过
__device__修饰符声明 - 使用
cudaMemcpyToSymbol()与cudaMemcpyFromSymbol()在主机端与设备端之间拷贝
#关系
-
与C中静态/动态数组的关系类似
int a[N]int *a = (int*)malloc(sizeof(int) * N)
-
动态
|
|
- 静态
|
|
#常量内存
- 存储于GPU DRAM中(与全局内存一样)
- 每个SM上有专用的片上缓存
- 常量缓存中读取的延迟比常量内存中低的多
- 在运行时设置
#使用
- 变量定义:使用
__constant__修饰词 - 值拷贝:使用
cudaMemcpyToSymbol()(与静态全局变量一致)- 用于少量只读数据
#常量内存访问举例
- 哪种访问更加有效率?
|
|
- 常量内存的最佳访问模式
- 基于blockIdx访问
- 所有线程访问同一内存(广播访问)
- 无串行访问
- 只需要一次内存读取
- 线程块中其他线程所需数据也同样会命中缓存
|
|
- 常量内存的最差访问模式
- 基于threadIdx访问
- 线程访问多个不同内存
- 需要串行访问
- 需要16次内存读取
- 线程块中其他线程所需数据可能不会命中缓存
#常量内存 VS 宏定义
- 宏定义由预处理器进行文字替换
- 不占用寄存器
- 存在于指令空间中
- 何时使用常量内存/宏定义?
- 宏定义中的值成为应用程序的一部分适用于编译后不再修改的值
- 常量内存适用于在执行中可能更改的值(在GPU代码执行过程中不变)