Brief introduction to cuda. Cuda的简单介绍。
#Flynn分类法
根据指令和数据进入CPU的方式:
- SISD
- SIMD
- MISD
- MIMD
拓展分类:
- SPMD 单程序多数据流,同样的可执行文件,但计算任务不同。(MPI)
- MPMD
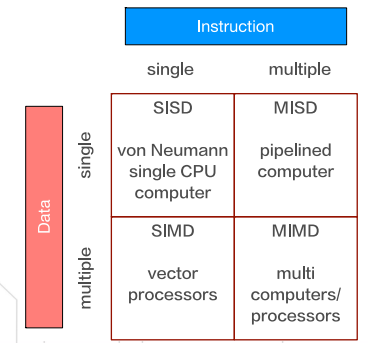 ※ Flynn分类法
※ Flynn分类法
SIMD与GPU最为相似
- 向量计算机
#分布式内存架构 VS 共享内存架构
- 分布式内存:MPI
- 多进程,进程之间是完全独立的,创建销毁开销大,通过消息传递接口通信
- 共享内存:Pthreads/OpenMP
- CPU线程,线程之间完全独立,创建销毁开销比较低,通过共享内存通信
- 共享内存:Cuda
- GPU线程,线程并不完全独立,创建销毁开销极低,多级存储
#CPU vs GPU
#性能
- 延迟:一个操作从开始到完成的时间(ms)
- 带宽:单位时间内,可处理的数据量(MB/s,GB/s)
- 吞吐量:单位时间内,成功可处理的运算量(gflops)
#CPU
- 目标:降低延迟(一个操作执行的速度快)
- 提高串行代码性能
- 适用于复杂单任务
- 类比:高速摩托车,飙车党
#GPU
- 目标:提高吞吐量(单位时间内多处理运算)
- 是并行架构
- 适用于大量相似任务
- 类比:大巴车,载着很多人到同一个目的地
#What is Cuda
Cuda是一种并行计算架构,旨在利用GPU的并行计算能力,用于通用计算。
#Heterogeneous Computing 异构计算
背景:经过 30 多年的发展,通过提升 CPU 时钟频率和内核数量来提高计算能力的传统方式遇到散热和能耗瓶颈。但是日益复杂的工作负载背后需要强大的算力进行支撑。
目的:更高的吞吐,更低的时延,更低的成本。
定义:使用不同类型指令集和体系架构的计算单元组成系统的计算方式
CPU+GPU就是其中一种异构计算系统,需要CPU和GPU协同工作。
#Host 主机 & Device 设备
主机:CPU及其内存
设备:GPU及其显存(设备内存)
通过在主机上调用核函数(kernel)执行并行代码
|
|
output:
Hello World from CPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
Hello World from GPU!
#CPU的特点
- 快速执行单一指令流。乱序执行、寄存器重命名、分支预测、越来越大的cache,这些设计都是为了加速单一线程的执行速度
- 每个核心只支持1或2个线程
- 切换线程的代价是数百个时钟周期
- 通过SIMD(单指令多数据)处理矢量数据
#GPU的特点
- 快速执行大量的并行指令流。处理器阵列、多线程管理、共享内存、内存控制器,这些设计并不着眼于提高单一线程的执行速度,而是为了使GPU可以同时执行成千上万的线程,实现线程间通信,并提供极高的内存带宽
- 对于支持Cuda的GPU,每个流处理器可以同时处理1024个线程
- 切换线程的代价是0,事实上GPU通常每个时钟周期都切换线程
- 使用SIMT(单指令多线程)处理矢量数据。SIMT的好处是无需开发者费力把数据凑成合适的矢量长度,并且SIMT允许每个线程有不同的分支
#CPU Threads & GPU Threads
GPU Threads的生成代价小,是轻量级的线程;CPU Threads的生成代价大,是重量级的线程。CPU Threads虽然生成的代价高于GPU Threads,但其执行效率高于GPU Threads,所以GPU Threads无法在个体的比较上取胜,只有在数量上取胜。在这个意义上来讲,CPU Threads好比是一头强壮的公牛在耕地,GPU Threads好比是1000头弱小的小牛在耕地。因此,为了保证体现GPU并行计算的优点,线程的数目必须足够多。
#nvcc
nvcc把源代码分成host部分和device部分
- host function(e.g. mykernel()) processed by standard host compiler, gcc, cl.exe
- device function(e.g. main()) processed by NVIDIA compiler
#Cuda 简单执行流
- Copy input data from CPU memory to GPU memory
- Load GPU program and execute, caching data on chip for performance
- Copy results from GPU memory to CPU memory
#Cuda编程模型
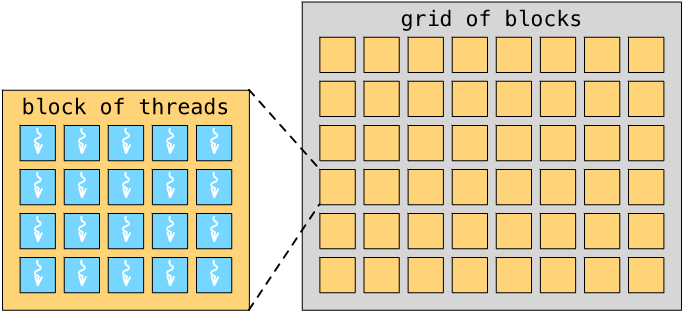 ※ Cuda编程模型
※ Cuda编程模型
#Thread 线程
每个线程执行相同代码,但是处理不同的数据。
#Block 线程块
线程被组织成线程块,一个线程块中有多个线程。一个线程块中的线程可以共享数据,并且可以同步他们的执行。
#Grid 网格
线程块被组织成网格,一个网格中有多个线程块。
|
|
#Cuda的异步性
- 与OpenMP不同,Cuda核函数为异步执行
- 调用核函数后,控制权会立刻返回给CPU
- CPU不需要等待GPU核函数的完成
- 有助于提高CPU和GPU的并行性,充分利用计算资源
#cudaDeviceSynchronize()
- Cuda提供的同步函数
- 调用后阻塞CPU的执行,知道GPU的所有核函数执行完毕
- CPU可以放心地继续执行后续需要依赖这些结果的操作